Berlin is a great city that used to have the reputation of affordable rents. While for sure other cities are still much more expensive, the rents in Berlin have risen considerably. Or so says everyone of my friends and my colleagues and so does it feel looking at renting listings. I decided to have a look myself at the data to find out if there’s still a secret neighborhood in Berlin resisting the raising prices and who knows, maybe the data can even tell us if the neighborhood Wedding is indeed “coming”.
For this, I will scrape the web page Immoscout for rental flats. It is the biggest platform in Germany, offering not just rental housing but also real estate. In this article, I concentrate on the rental offers, but only minor changes would be needed to scrape houses for sale.
url <- "https://www.immobilienscout24.de/Suche/S-2/Wohnung-Miete"For scraping, we will use the library rvest.
library(tidyverse)
library(rvest) # for scraping
library(stringr) # for string manipulation
library(glue) # evaluate expressions in strings
library(jsonlite) # to handle json dataNow if we look at the URL, then it has a list of offers and at the bottom, we can select the page via drop down menu or go to the previous or next page.
Our task will now be to iterate over all pages and get all listings from each page. For this, we will need to look at some HTML and CSS code.
The easiest way to do is, is to have a look at the source code in your browser (if you use Chrome, just press F12). If you then hover over the elements, you can see the corresponding source code. Since we want to know, how many pages of listings there are, we have a look at the drop down menu at the bottom:
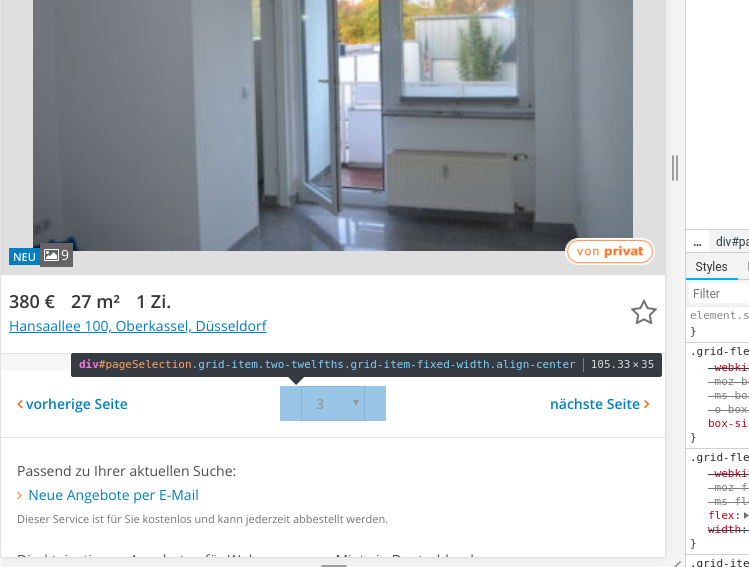
If you know a bit of HTML, then you know that <div> represents an HTML node for a division or section. Other HTML nodes are for example
<h1>,<h2>etc for headings<p>are paragraph elements<ul>is an unordered list (such as this one) where each item is denoted with<li><ol>is an ordered list<table>is a table (surprise)
The usual structure in an HTML file is such, that the tag for a node embraces its content: <tag>content</tag>.
To access any HTML node, we use the function html_nodes(). We load in the first page and then access any HTML node as follow:
first_page <- read_html(url)
first_page %>%
html_nodes("div") %>%
head(2){xml_nodeset (2)}
[1] <div class="viewport">\n \n\n\n\n\n\n\n\n\n\n<div class="page-wrapper ...
[2] <div class="page-wrapper page-wrapper--with-ads page-wrapper--no-borders ...We’re not actually interested in all divisions but only the one with the ID "pageSelection". To get this specific node, we use # to denote that it’s an ID. In this division, there is a select node which contains all options. We access the nested nodes as follows:
first_page %>%
html_nodes("#pageSelection > select > option") %>%
head(2){xml_nodeset (0)}From this, it is now easy to obtain the last page number. With html_text(), we extract the values for each node as text, which gives us a vector of page numbers. The length of this vector is the number of pages:
(last_page_number <- first_page %>%
html_nodes("#pageSelection > select > option") %>%
html_text() %>%
length())[1] 0As next step, we generate a list that contains the URLs of each page. At this website, the page number is inserted somewhere in the middle of the URL for which we use the package glue. Glue expressions in curly braces in strings, similar to Pythons f-strings:
page_url <- "https://www.immobilienscout24.de/Suche/S-2/P-{pages}/Wohnung-Miete"
pages <- 1:last_page_number
page_list <- glue(page_url)Now that we have a list for all page urls, we need to find out how to actually get the information of each listing. Going back to the source code of the website, we see that the listings are contained in an unordered list (<ul>) with the ID "resultListItems" where each listing is a node with the tag <li>.
first_page %>%
html_nodes("#resultListItems > li") %>%
head(2){xml_nodeset (2)}
[1] <li class="result-list__listing " data-id="115913296"><div><article data- ...
[2] <li class="result-list__listing " data-id="115913421"><div><article data- ...We now see that the first item in the list is not actually a listing but a banner. The listings are of the class result-list__listing. To extract only the nodes of a certain class, we give the parameter .class-name to html_nodes(). So to get only the listings, we give the parameter .result-list__listing:
first_page %>%
html_nodes(".result-list__listing") %>%
head(2){xml_nodeset (2)}
[1] <li class="result-list__listing " data-id="115913296"><div><article data- ...
[2] <li class="result-list__listing " data-id="115913421"><div><article data- ...Perfect, now we have a list of all listings.
We could now either just scrape the information for each listing that is displayed on the front page (such as total rent, number of rooms etc) or get the link to the listing and scrape the information (with more details) from the full listing. We will do the second option here.
Looking again at the source code, we find the following <a href="/expose/123456">. That means, the link is given as a relative path and has the same form for each listing. The number in the link is also given as data-id as attribute in the <li> node. The attributes of a node are not part of the node content (and hence are not output via html_text()). In rvest, we access attributes using the function xml_attr().
(listing_ids <- first_page %>%
html_nodes(".result-list__listing") %>%
xml_attr("data-id")) [1] "115913296" "115913421" "115822781" "115875230" "115913255" "115913254"
[7] "115913252" "115913251" "115913250" "115913238" "115913240" "115913235"
[13] "115913228" "115913227" "115913166" "115913226" "115913224" "115913223"
[19] "115913221" "115913214"This gives us all the information we need to create a list of all listing IDs:
listing_url <- "https://www.immobilienscout24.de/expose/"
listing_list <- str_c(listing_url, listing_ids)In the next step, we need to extract the relevant information from one flat listing. Again, we need to look at the source code. Rather hidden in the code is somewhere a dictionary called keyValues that contains all information about the flat in a compact format. Since it is actually in some javascript code, I found it easiest to just transform the whole page via html_text() to a string and then extract the dictionary with some regex.
Let’s do this exemplary for the first listing:
list_page <- read_html(listing_list[1])
list_l <- list_page %>%
html_text() %>%
str_extract("(?<=keyValues = )(\\{.*?\\})") %>%
str_remove_all("obj_") %>% # to save some typing later on
str_replace_all("false", "FALSE") %>%
str_replace_all("true", "TRUE") %>%
fromJSON()If you wonder what the cryptic regex means, here is a very rough breakdown: The first group, that is the first parentheses, looks for the pattern "keyValues = " to then check if whatever comes afterswards matches with the second parentheses. This is called a positive lookbehind. The second group matches everything in curly braces. Since regex is something I can never quit remember for long, I usually just go to this page, copy paste the text in which I’m searching a certain pattern and then try until I find something that works. Unfortunately, the page only has a few regex flavors, but the python flavor seems to be close enough. One difference in R is, that to escape special characters, you need two backslashes instead of the usual one.
Back to the listings, there are two information I would like to have that is not contained in the dictionary: The text description of the object and the text about the facilities. Luckily, there are much easier to find than the dictionary:
list_l$description <- list_page %>%
html_nodes(".is24qa-objektbeschreibung") %>%
html_text()
list_l$facilities <- list_page %>%
html_nodes(".is24qa-ausstattung") %>%
html_text()For identifiability reasons, we should also add the ID of the listing itself. This way, we can later have a look at the listing page again.
list_l$id <- listing_ids[1]For further analysis, we then transform the list to a data frame:
list_df <- list_l %>%
map_if(is_empty, function(x) {
NA
}) %>%
as_tibble()Let’s wrap this up in a little function:
get_listing_data <- function(listing_url) {
list_page <- try(read_html(listing_url))
if (any(class(list_page) == "try-error")) return(NULL)
list_l <- list_page %>%
html_text() %>%
str_extract("(?<=keyValues = )(\\{.*?\\})") %>%
str_remove_all("obj_") %>% # to save some typing later on
str_replace_all("false", "FALSE") %>%
str_replace_all("true", "TRUE") %>%
fromJSON()
list_l$description <- list_page %>%
html_nodes(".is24qa-objektbeschreibung") %>%
html_text()
list_l$facilities <- list_page %>%
html_nodes(".is24qa-ausstattung") %>%
html_text()
# extract id back from url
list_l$id <- str_extract(listing_url, "(?<=/)\\d+")
list_l %>%
map_if(is_empty, function(x) {
NA
}) %>%
as.tibble()
}The hard part is almost done. So far, we only have a single data point. We now need to piece everything together and loop over all pages and listings and scrape together the information.
for (i in 1:last_page_number) {
link <- page_list[i]
page <- try(read_html(link))
if (!any(class(page) == "try-error")) {
listing_ids <- page %>%
html_nodes(".result-list__listing") %>%
xml_attr("data-id")
listing_url <- "https://www.immobilienscout24.de/expose/"
listing_list <- str_c(listing_url, listing_ids)
map(listing_list, get_listing_data) %>%
bind_rows() %>%
write_csv(paste0("../../rohdaten/", format(Sys.time(),
"%Y-%m-%d-%H%M%S"), " page ", i, ".csv"))
}
}Now, since the process of scraping is rather slow, I used the library foreach to run the whole thing in parallel. This only requires a few small changes to the code above. I’m no expert on parallel computing, but apparently it is needed to first register the multicore parallel backend which is done by the package doMC. Note that the parallel backend is system-specific, so if you run Windows or Mac, you will need a different library. Also, since the files are generated in parallel, the time stamp is not a good file name for sorting the files by page, so I instead put the page number at the front of the file name.
Even with the parallel backend, going through all pages takes quite a while (depending on your internet connection), for me it was more than a day so at some point I just decided that I had collected enough data and stopped the script.
Edit: I ran the script again some months later and it took less than 3hs, so I probably had really bad internet the first time.
library(foreach) # to run in parallel
library(doMC) # backend to run in parallel (only for linux)
n_cores <- detectCores()
registerDoMC(n_cores)
foreach(i = 1:last_page_number) %dopar% {
link <- page_list[i]
page <- try(read_html(link))
if (!any(class(page) == "try-error")) {
listing_ids <- page %>%
html_nodes(".result-list__listing") %>%
xml_attr("data-id")
listing_url <- "https://www.immobilienscout24.de/expose/"
listing_list <- str_c(listing_url, listing_ids)
map(listing_list, get_listing_data) %>%
bind_rows() %>%
write_csv(paste0("../rawdata/", str_pad(i, 4, pad = "0"), "_",
format(Sys.time(), "%Y-%m-%d-%H%M%S"), ".csv"))
}
link
}The full R script can be found here.
So now, let’s see if my dream flat is somewhere hidden in the scraped data.